Après avoir parlé du roman Le Maître ou le tournoi de Go nous allons ici regarder La joueuse de Go, prix Goncourt des Lycéen 2001.
Plus que le roman lui-même (on peut déjà en gérer les informations) c’est plutôt des articles de presse et des émissions de télévision dont nous allons parler.
Tout cela étant en lien avec la problématique de la revue de presse et le fait que j’ai lancé le projet.
Objet d’étude
Voici les informations que l’on va essayer de gérer en base :
- SHAN Sa à propos de son livre « La joueuse de go » (France 3, 24/10/2001)
- Shan Sa pour « la joueuse de go », Goncourt des lycéens 2001 (lemonde.fr, 12/11/2001)
- Le Prix Goncourt des lycéens connu aujourd’hui (Le Parisien, 12/11/2001)
- La joueuse de go (L’Express, 01/12/2001)
- Shan Sa, impératrice des lycéens (L’Express, 10/12/2001)
- Shan Sa, la joueuse (L’Express, 06/12/2001)
- Shan Sa, la joueuse de Go (France 3, 01/03/2003)
- La joueuse de go, de Shan Sa (pitou.blog.lemonde.fr, 01/01/2006)
Si on laisse de côté les émissions de télévision, pour les articles dans la presse il s’agit de documents dans des publications qui ont un International Stantard Serial Number (ISSN) :
| ISSN | Nom |
|---|---|
| 1950-6244 | LeMonde.Fr |
| 0395-2037 | Le Monde |
| 0014-5270 | L’Express |
Quand on pense qu’un blog comme Science étonnante a un ISSN, on pourrait se dire qu’il s’agit d’un bon identifiant. Oui mais, ça n’est pas le cas de tous les journaux ou sites web pour lesquels on voudra indexer du contenu.
Et puis, même si c’était le cas, il pourrait être contraignant d’avoir à chercher l’ISSN pour indexer ; sans compter que cela ne convient pas forcément aux chaînes de télévision. Il va donc falloir que je définisse un identifiant de mon cru :
| InformaGOlog_code | ISSN | Nom |
|---|---|---|
| LEMONDE.FR | 1950-6244 | LeMonde.Fr |
| LEMONDE | 0395-2037 | Le Monde |
| LEXPRESS | 0014-5270 | L’Express |
| FRANCE3 | FRANCE 3 (National) |
Dans le cas des publications en ligne, cela revient à prendre l’URL du site principal.
L’URL, vraiment ?
Au départ, je pensais que c’était une mauvaise idée de faire cela, puisque dans le cas des pages web cette informations est déjà contenue dans l’URL. De même, utiliser une chaîne de caractère et non un identifiant numérique n’est pas très optimisé.
Sur le premier point j’ai pu constater qu’il était utile d’avoir un identifiant intelligible, surtout si on peut le retrouver dans se référencer à une autre table ; et pour ce qui est de l’optimisation en stockage ou temps de calcul … il sera toujours le temps de se poser le moment venu (on parle d’une base locale).
Je pense donc que c’est une solution viable. Enfin, pour ce qui est des journaux …
Quel identifiant pour les publications ?
Là est bien le nœud du problème : s’il est raisonnable de penser que deux revues/journaux n’auront pas le même nom, il n’en va pas de même pour des articles ou émissions de télévision.
Mais avant cela il convient d’identifier l’objet du crime, ou plutôt les classes :
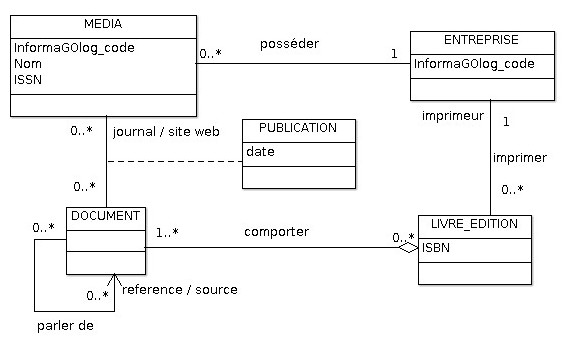
Comme pour les livres, dont on différencie l’EDITION du texte qu’il contient (le texte étant un DOCUMENT), on a ici DOCUMENT et PUBLICATION.
Je ne sais pas si au sens d’un modèle sémantique (Praxeme) c’est correct, mais cela évite d’avoir à gérer des liens (ARTICLE-ARTICLE), (ARTICLE-LIVRE), … Et puis au final c’est aussi bien de pouvoir indexer n’importe quoi dans DOCUMENT.
Bien, il reste à définir cet identifiant ! Je propose :
- Page web => URL
- Autre => MEDIA[+NUMERO ou DATE]|TITRE
Prenons l’exemple de l’article Perec ne jouera plus …, paru dans la RFG n°14 et dont le texte a été repris sur le blog : REVUEFRANCAISEGO014|PERECNEJOUERAPLUS
Et pour les émissions de télévision :
- FRANCE3|SHANSAAPROPOSDESONLIVRELAJOUEUSEDEGO
- FRANCE3|SHANSALAJOUEUSEDEGO
C’est un peu long, mais au moins cela permet d’être à peu près sûr d’avoir un titre unique ; et cela prendre en compte le fait que parfois des articles d’un même titre paraissent plusieurs numéros d’une revue.
Reste maintenant à voir si cette idée fonctionne sur les articles de la revue de presse (et confirmer qu’elle convient pour les EMISSION de télévision).